There is a quiet assumption buried in the classical complexity analysis of geometric algorithms: that every instance is equally surprising. The $O(n \log n)$ lower bound for two-dimensional Delaunay triangulation—a result that has stood as the canonical benchmark of computational geometry for decades—is a worst-case statement, and worst-case analysis makes no distinction between a random point cloud and one that differs from the previous step of a simulation by a single vertex displacement.
In many real applications, this assumption is dramatically wrong. In iterative mesh refinement, in real-time physics simulation, in the dynamic triangulation of evolving sensor data, the geometry at step $t+1$ is almost always very close to the geometry at step $t$. An algorithm that does not exploit this nearness—that rebuilds the Delaunay triangulation from scratch at every frame—is discarding information that is readily available.
Learning-augmented algorithms are one response to this waste. The broad idea is to provide the algorithm with a "prediction" of the correct output—a guess derived from prior computation, a neural predictor, or some domain-specific heuristic—and then build a routine that runs faster when the prediction is accurate, while retaining correctness guarantees when it is not. A recent paper by Sergio Cabello, Timothy M. Chan, and Panos Giannopoulos, titled "Delaunay Triangulations with Predictions," applies this framework rigorously to one of computational geometry's most studied structures.
The Distance Between Triangulations
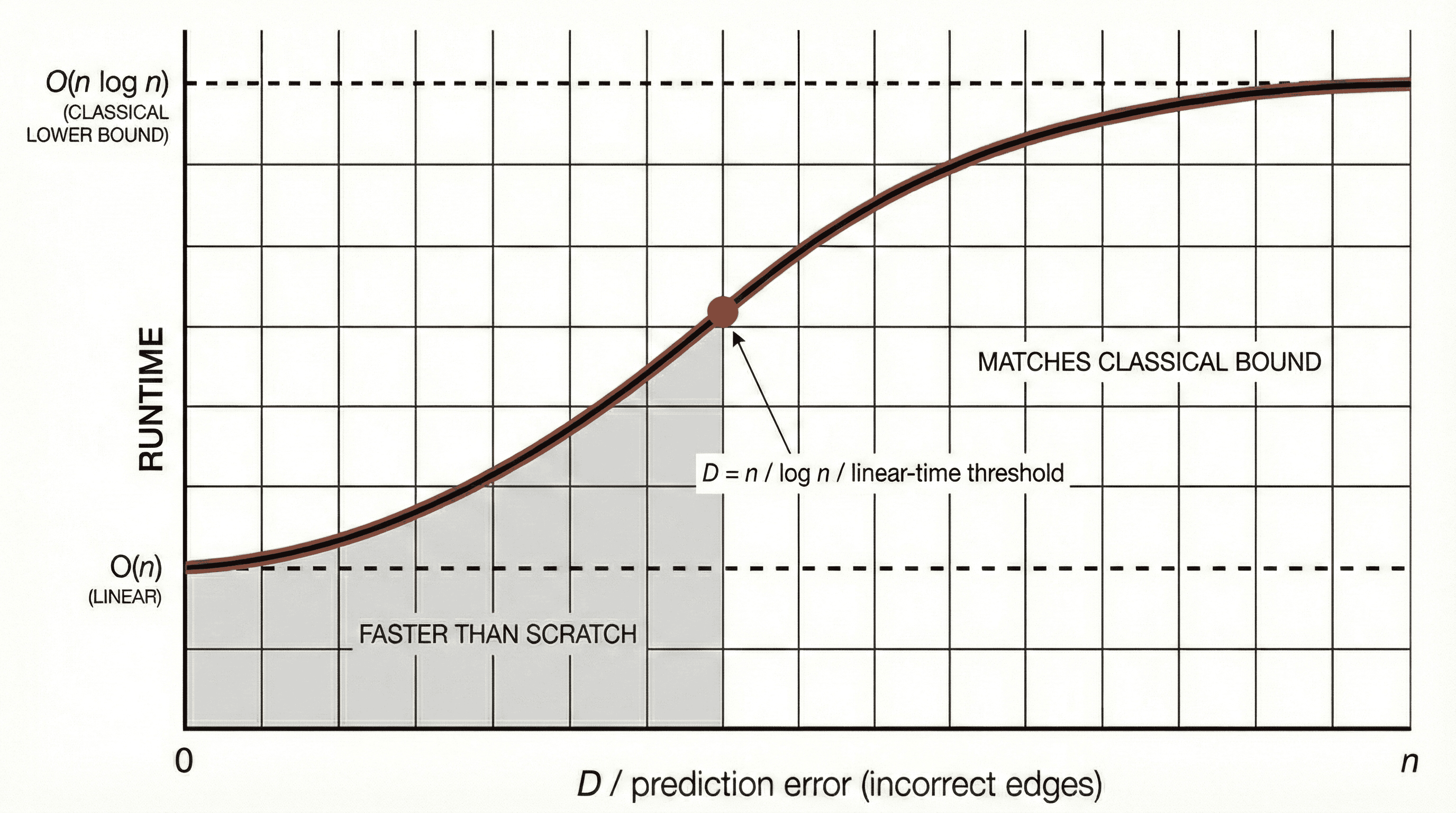
The framework requires a way to measure how wrong a prediction can be. The authors introduce several such measures, the most natural being $D$: the number of edges in the predicted graph $G$ that do not belong to the true Delaunay triangulation $DT(P)$. A perfect prediction has $D = 0$; an adversarial one has $D = O(n)$.
For a randomized algorithm, the key result is a running time of $O(n + D \log n)$—and this is proven to be optimal. When the prediction is perfect, the triangulation is recovered in linear time; when it is completely wrong, the algorithm degrades gracefully to $O(n \log n)$, no worse than computing from scratch. The practical implication: for any iterative geometric workflow in which consecutive states are similar, and in which the number of "wrong" edges $D$ grows slower than $n / \log n$, the Delaunay triangulation can be maintained in linear time per step. For real-time simulation, this is the difference between interactive and non-interactive.
"The most fruitful question is not how fast an algorithm runs in the worst case, but how fast it runs when the instance is similar to one it has already seen—and how gracefully it fails when the prediction is off."
Beyond Simple Error Counts
The paper does not settle for a single error model. Beyond the edge-count metric $D$, the authors explore a probabilistic framework in which $G$ contains a random subset of correct edges, with the remainder filled in adversarially. Even in this mixed-trust environment, they present a deterministic algorithm sensitive to the maximum number of points violating any triangle's circumcircle. The approach draws on planar graph separators and $r$-divisions—tools from static graph theory that, in this context, serve as instruments for quarantining the regions of the triangulation most likely to require local repair.
For the computational designer, the implications are practical and broad. Topology optimization, lattice structure refinement, and surface reconstruction from evolving sensor data are all domains where Delaunay computation recurs at every iteration. The ability to exploit similarity across those iterations—not approximately, but with rigorous theoretical backing—changes the cost structure of these pipelines in meaningful ways.